Word2Vec For Emojis: Enrich Word Embeddings for Better CSAT
Word2Vec For Emojis: Enrich Word Embeddings for Better CSAT
Emojis constitute an important part of the text and are often ignored. However, using them in ML models often boost performance.
Emojis have been around since 2010, but their popularity has grown when Apple released the official emoji keyboard. Emoji usage surged by almost 800 per cent in 2015. More than 60 million emojis are used on Facebook every day, and more than 5 billion are sent on Messenger every day, according to Facebook statistics from 2017.
Emojis may also provide a lot of insight into text sentiment because they are so widely used and most of them have emotions built-in.
Word Embeddings
Language understanding, a relatively easy task for humans, is quite difficult for machines. The different relationships of words like king-queen, man-woman, shirt-pant etc are something we understand intuitively.
Word embeddings are a form of word representation that allows a machine to understand these relationships by simply converting each word to an n-dimensional vector space. Words that have the same meaning have a similar representation and therefore, are close to each other in the vector space.
Word2vec is a method to efficiently create such kind of word embeddings. The most intriguing aspect of these embedding vectors is that they will have comparable embedding vectors for words with similar meanings or contexts.
We will proceed to use the Word2vec model for generating embeddings for emojis.
Deep dive into Word2Vec
Word2vec can be trained using two types of model architectures: CBOW(Continuous Bag of Words) and Skipgram.
CBOW (Continuous Bag of Words)
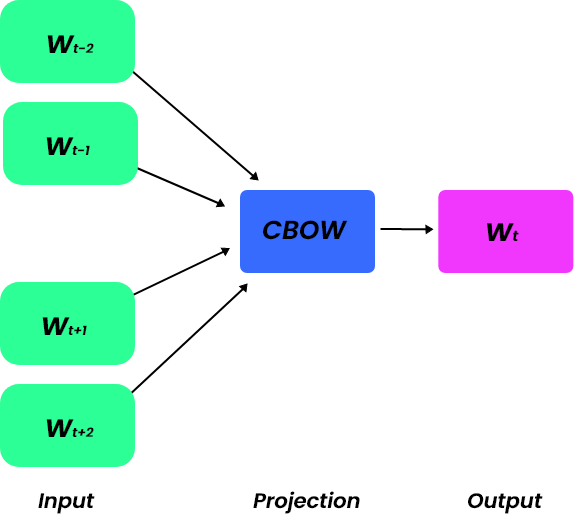
In CBOW, word2vec uses context (or surrounding) words to try to predict the target word. For example, let’s consider a sentence – “Cat is running down the street.” Word2vec tries to predict the word “running” based on the previous two and next two words (in case the window size is 5). The word “running” serves as the focus, while the words ” cat, is, down, the” serve as the context. This strategy works best for words that are used frequently.
Skipgram
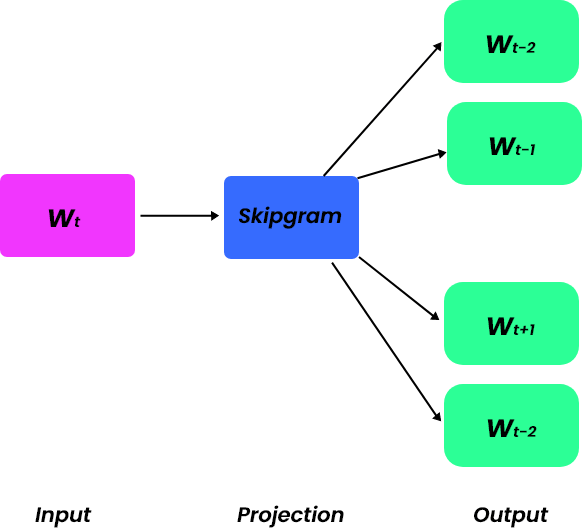
Skipgram is the reverse of CBOW. It uses the target word to predict context words. Assume we use the same example as CBOW. Using the word “running” word2vec tries to predict context words. Because skipgram is better for unusual words, it is used more frequently. We will do a little more analysis of how that works.
Below is an illustration of the skipgram workings with a sliding window(size=5).
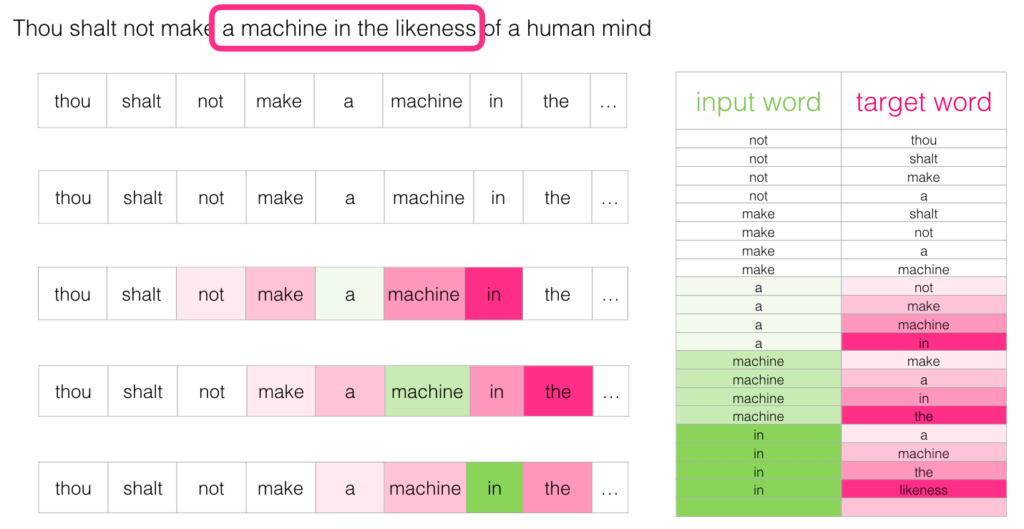
In the above image we can see if the current word is “a” then we have context words( ‘not’, ‘make’, ‘machine’, ‘in’) as targets. As the sliding window moves, we get lot more examples.
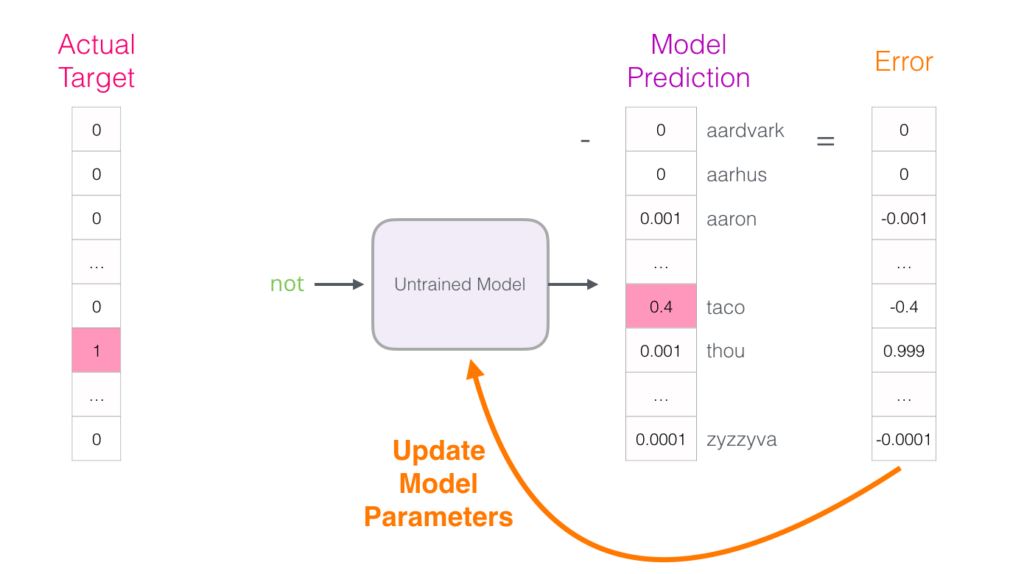
Given an input word, the model will try to predict context/neighbouring words. It will calculate the softmax probability for each word in the vocabulary for each sample.
Model prediction is the output of the following equation. It is a softmax of the dot product of the target word and input word.

The loss is then calculated using the following equation which is the difference between the prediction vector and the actual vector. A negative log of likelihood is given below
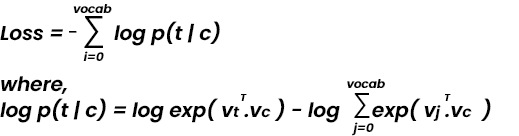
The need for Negative sampling
One of the major drawbacks of the skipgram method is that it requires us to calculate softmax probabilities for each word in the vocabulary based on a single input. And it’s computationally expensive to do this for each sample. We can use skipgram method with Negative sampling to overcome this.
Rather than taking input and predicting output, we take input and output words and determine whether they are neighbours (0 for “not neighbours” & 1 for “neighbours”).

If you recall how we generated data for skipgram by dragging a window over the text, all words will now be neighbours. Since the data consists of only neighbours, the model will learn to predict only 1 class and embeddings won’t generate anything useful.
To circumvent this issue, we introduce something called negative sampling. We’ll add some samples that aren’t neighbours, with a label of 0.
And the approach to do this would be – for the same input word, choose a random target word from the vocabulary.
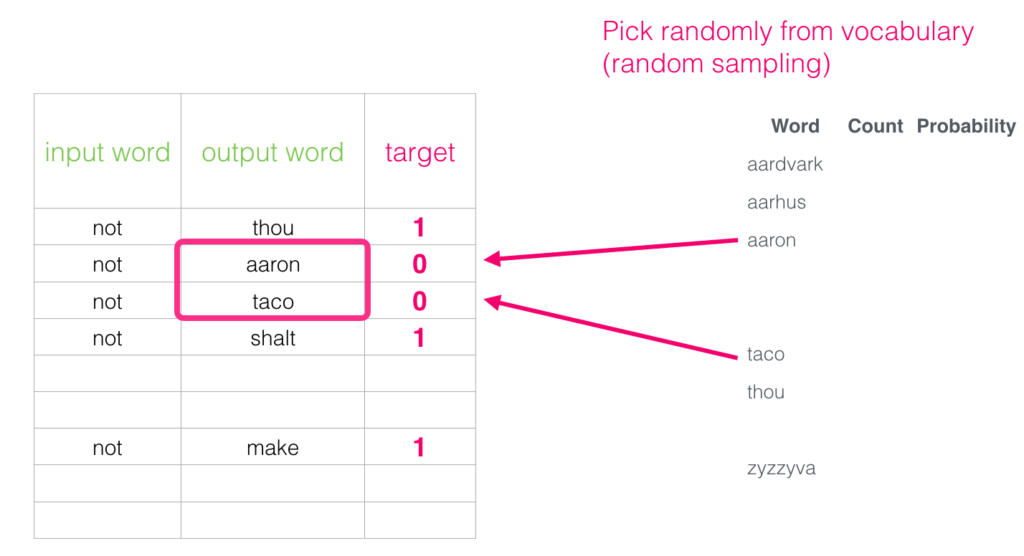
Here “Number of negative samples” is the hyperparameter to set. In the word2vec publication, Mikolov stated that for smaller datasets, it should be between 5 and 20, whereas, for larger datasets, it should be between 2 and 5.
A quick look at training Word2vec (With skipgram and negative samples)
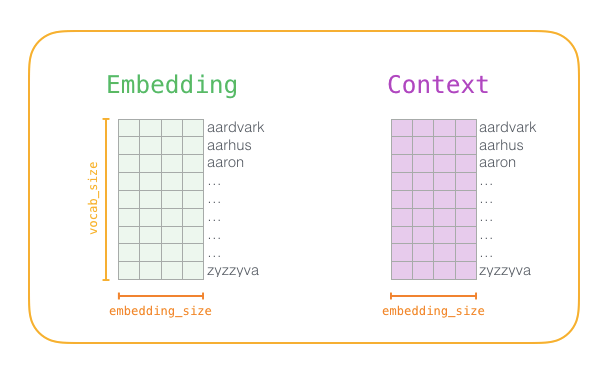
- Create two matrices embeddings and context. One dimension is vocab size and second is embedding size (common embedding size is 300). These matrices are initialized randomly at start. We have two matrices for each word because it turns out that it makes the math easier and also works better this way.
- For each step we take one positive sample and its associated negative samples.
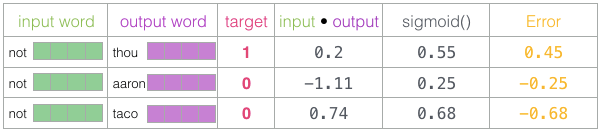
- Now taking dot product of embedding vectors of input word and output word we get the output.
- To convert that output to probability apply sigmoid on that output. Here instead of taking softmax over whole vocab we take each word and apply the sigmoid function to predict a probability.This is why it is faster and computationally less expensive.
- We then calculate the error/loss. It is the difference between target and probability.
- Now that we have the loss we can use optimizers like gradient decent or SGD to optimize and reduce the loss.
Generating embeddings for Emojis
The same approach can be used for emojis as well. Embeddings for the emojis will be based on the context words around them.
Let’s take an example:-
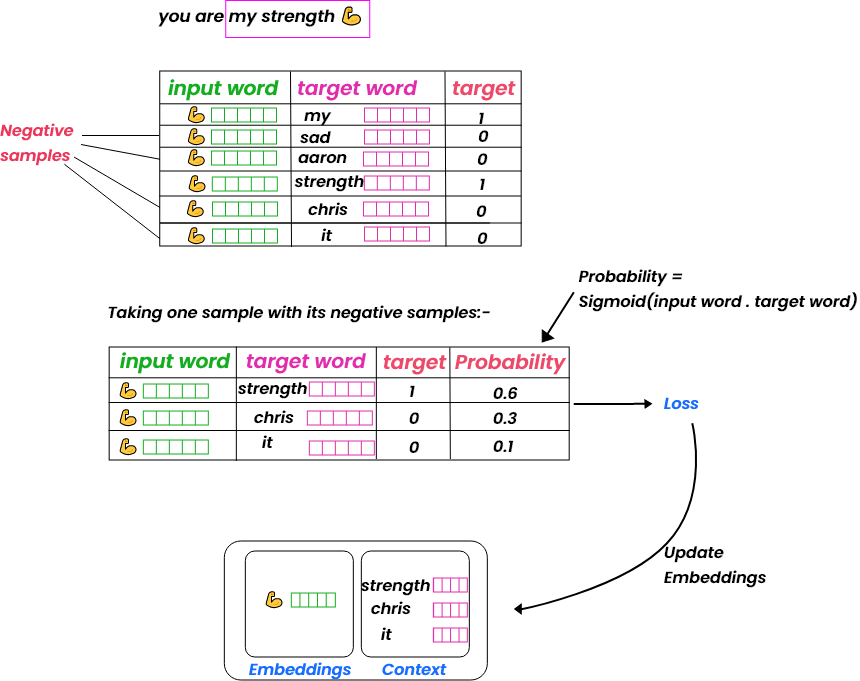
- Both embeddings and context vectors are randomly initialized at the start.
- We then proceed to create the dataset of input word, context and target. We also create the negative samples for each input word
- Taking one positive sample and its associated negative samples, we make a prediction which is the dot product of input and target word vectors.
- We use the sigmoid function to convert that output to probability and finally calculate the loss/error. to update embeddings.
Results
We used the gensim library to train a word2vec model using Twitter data. Emoji vectors will be based on where users have used emojis in their tweets in this scenario. Word2vec was trained with a window size of 5, an embedding output size of 300, and a negative sample size of 5.
We can visualize trained embeddings using Tensorflow’s amazing tool called Embedding Projector. It converts any dimension of the vector into 3D using PCA(Principal Component Analysis). The following is a representation of all words in the vocabulary that contain words and emojis. This allows us to see which words are similar to which words or emoji.
Visualizing only the emojis embeddings below.
When we give word “cat” and only look at most similar emoji embeddings we get cat emoji with almost 65% match.
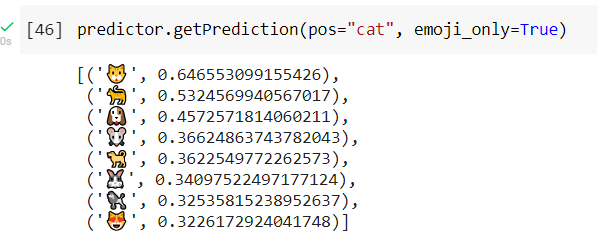
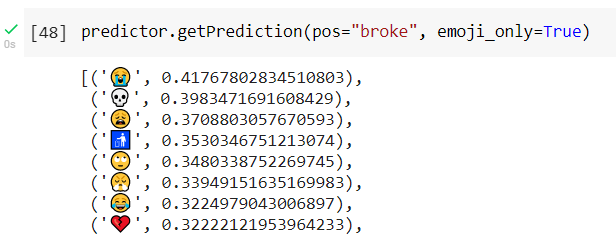
We can also compare the similarity of two words or emojis.

Other approaches of learning Emoji Representations
Emoji2vec: Learning Emoji Representations from their Description
This research utilized a different technique to create emoji vectors than the previous one. Rather than using random text from the internet including emojis, such as tweets or Instagram posts, they used official Unicode descriptions and keyword words for each emoji to generate 6088 descriptions for 1661 emoji symbols.
And then for each word in description and keywords, they used google news word2vec embeddings and to create an embedding vector for that emoji they summed them all together.
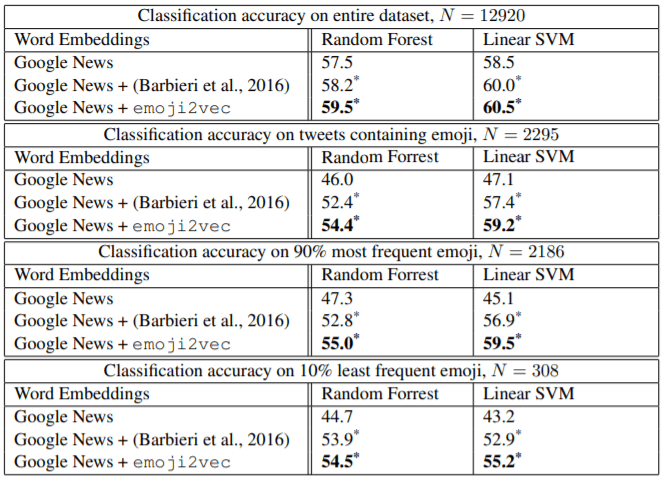
When classifying tweets from a dataset of 67,000 English tweets that were manually labelled positive, neutral, or negative, they discovered that using their emoji2vec emoji embedding for sentiment analysis outperformed models using only word2vec. They also found that it outperformed the skip-gram method described above.
Here are comparison results are shown in the official paper:-
They projected the learned emoji embeddings from 300-dimensional space into 2-dimensional space using t-SNE (t-Distributed Stochastic Neighbor Embedding), a method that attempts to preserve relative distances in lower-dimensional spaces.

Conclusion
Emojis hold a wealth of information that can be tapped for various purposes like sentiment classification. Training and retrieving emoji embeddings along with text embeddings can enrich the word embeddings. As chat interfaces start offering more conveniences to customers to allow chatting using various channels like WhatsApp and Facebook, the usage of emojis has become more prevalent and can be used for better prediction of overall customer satisfaction. Models like Word2Vec offer a good starting point to train these kinds of embeddings.

References:-
- Link to code – GitHub – AdiShirsath/Emoji_Word2Vec: Training word2vec model for emojis
- The Illustrated Word2vec [Blog]
- Distributed Representations of Words and Phrases and their Compositionality [pdf]
- Lecture 2 | Word Vector Representations: word2vec [Video]
- Understanding Word2Vec [Video]
- emoji2vec: Learning Emoji Representations from their Description.[pdf]
- Emoji2vec [Blog]
- GitHub – uclnlp/emoji2vec: emoji2vec: Learning Emoji Representations from their Description [GitHub]