How Verloop.io Improved its ASR Accuracy with Error Correction Techniques

How Verloop.io Improved its ASR Accuracy with Error Correction Techniques
Voice-based conversational AI solves customer queries by providing relevant answers. It entails a series of steps – audio is converted into text, natural/spoken language understanding models extract relevant intents and entities from the text and finally, a suitable response is framed for the user.
This necessitates the need to have good ASR systems for building a robust Voice AI.
Such systems therefore should
- Have a high level of accuracy
- Be able to work well across domains and correctly identify specific words/phrases spoken in specific domains
One of the biggest challenges while building a voice assistant is to mitigate the impact of errors introduced by the ASR systems. The ASR errors have a cascading effect on language understanding models and end up harming downstream tasks.
A common metric to measure ASR performance is the Word Error Rate (WER). The Word Error Rate is defined as the percentage of the total number of inaccurately translated words including insertion, deletion and substitutions, made by the ASR to the total number of words that should have been present if the translation was 100% accurate. Current cloud provider ASR models have WER in the region of 20-30% on call recordings.
The errors are normally low when generic sentences are used. However, these tend to be high as 35% when domain-specific sentences are spoken. This number increases further if the speaker’s dialects & environment become too noisy or deviate a lot from the training data. Also most of the cloud provider ASR models fail to pick up Organization’s name, Indian names, and abbreviations, merge two words into one when they are phonetically similar, and delete words in noisy environments.
Out of these, some can be corrected, while some are much harder. Making mistakes in names for instance is not easily rectifiable, however, phrase substitutions are easier to correct.
While ASR systems give decent accuracy for commonly spoken words, they however fail to recognize domain-specific words. For example:
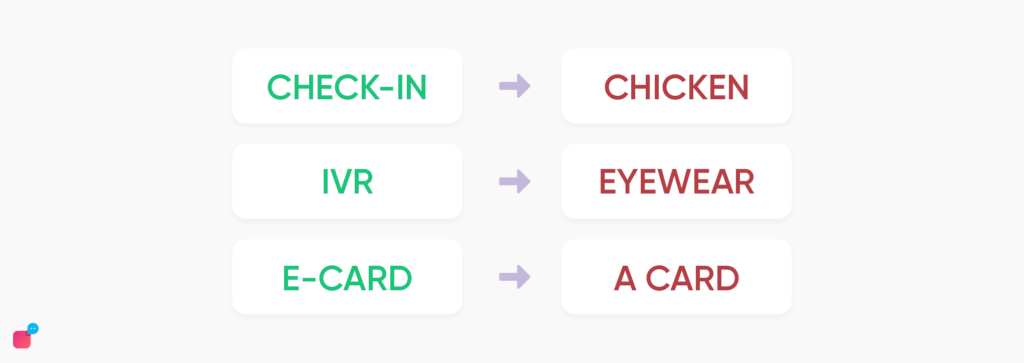

If the first step produces erroneous results, the subsequent parts ie. the responses also suffer.
One solution is to train custom models for each domain. However, training custom models for every domain can prove to be hard due to the limited availability of annotated data for such tasks.
The other method is to use domain-specific post-processing techniques. Post-processing techniques can be implemented either using deep learning models or using simpler classical techniques.
We experimented with various options for post-processing which were suitable for low-latency requirements. We also experimented with deep learning approaches using BERT-based models and T5 for predicting the correct sentence. In this blog, we talk about some of our experiments using classical methods.
ASR Post-Processing
The post-processing technique can be divided into two parts:
- Detecting the error word/phrase
- Replacing the error word/phrase with the correct word/phrase
Detecting Error Words:
The first step in correcting the transcribed text is to detect the places where the ASR has made mistakes. We experimented with various approaches and a probability-based KL-Divergence model worked well, wherein we calculate the KL-Divergence for each word and if it’s above a threshold, the word is marked as incorrect [1]. The kl-div is calculated as:
D(p||q) = Σ p(x)log(p(x)/(1-p(x))
where p(x) is the conditional probability of the co-occurrence of the target word
with a context word x in the set of c context words X.
A dataset containing 60k samples of user chat utterances was used, to train our KL-Div model. We used a sliding window technique on our chat utterance, with the centre word being the target word and the surrounding word being the context words, for eg-> “Hello my name is Shivam Raj”, using a window size of 5, the window comprises of “Hello my name is Shivam” with the middle word “name” is considered as the target word and the words “Hello”, “my”, “is” and “Shivam” are considered as the context words. Using the whole training corpus we calculate each word’s probability and the conditional probability of the word occurring given the context word.
At the inference time, the actual text being “I want to check in the hotel” is converted to “I want to chicken the hotel” by the ASR system. Using a window of size 5, with context words “want”, “to”, “the”, “hotel” and the target word being “chicken” we see that the word chicken never came with the words like “want”, “to”, “the”, “hotel” in training data, giving it a high KL divergence value, and hence marking it as an incorrect word.
Finding Replacement Words:
Once the incorrect word is found, the next step is to replace it with a suitable correction. We checked with pure probabilistic approaches & distance-based approaches for finding a suitable substitute word but the accuracy was low.
To tackle this, a pre-filtering technique was added, filtering out the words from the corpus which could be adding noise and degrading our results. For this the training data samples were used to construct a trie-based suggestion, using the past and the future context for example,
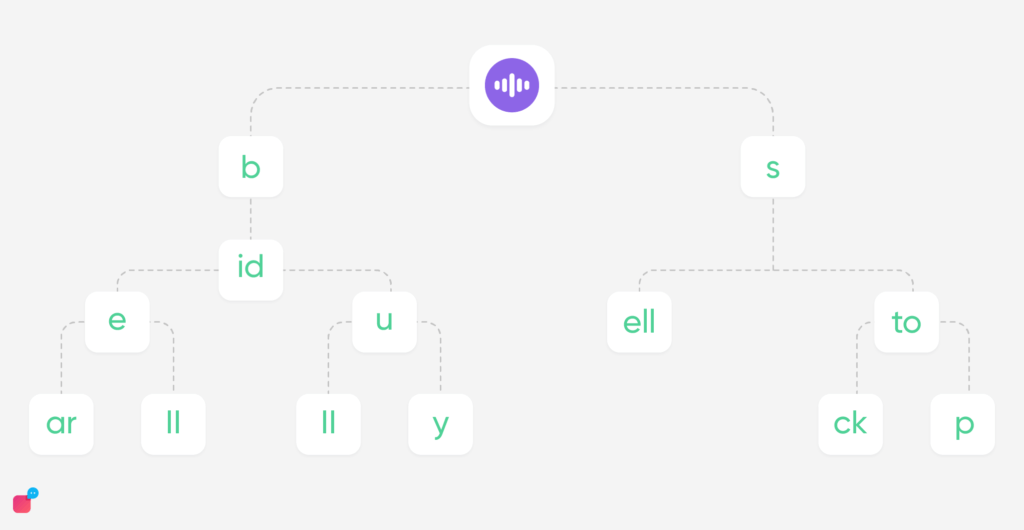
If the past context is “book my” the suggestions are words that came up next after “book my” in our training corpus, like “ticket”, ”room ” etc. This narrowed down the candidate words, considering only the trie-based suggested words for replacement. At the inference time, if an ASR transcribed text “book my limit” comes in, we use “book my” as the past context, and all suggested words from the trie as possible replacement candidates for the word “limit”. Within these candidate words, we search for our correct replacement word using the weighted function of phonetic and word distance. Using this approach we were able to replace errors with an accuracy of 31% improving our overall ASR text prediction.
Suggested read: Chatbot SDK: What is it and Why Should it be Updated?
Conclusion
The experiments conducted using the post-processing techniques evidently showed a 31% improvement in WER after post-processing on our custom dataset. The WER prior to any post-processing came out to be 27% and was further reduced to 19% after post-processing.
While using a Deep Learning approach can work well when there’s a lot of domain-specific training data available, it can still turn out to be expensive owing to its heavy computation and latency requirements imposed by a real-time system.
Our technique is built upon the traditional methods using the trie data structure, phonetic distances, probabilistic models, and KL-Div approaches. This makes it fast and can easily be utilized in the existing pipelines. It also obviates the need to train & maintain custom models for each domain/client.
References:
[1] Arup Sarma and David D. Palmer. 2004. Context-based Speech Recognition Error Detection and Correction. In Proceedings of HLT-NAACL 2004: Short Papers, pages 85–88, Boston, Massachusetts, USA. Association for Computational Linguistics.